How Serverless Spark Streamlines Data Analytics on Google Cloud Solutions
Drive speed, efficiency and flexibility in data processing through autoscaling serverless technology on Google Cloud
Aug. 31, 2022 | By Hemanth Aaileni, Software Engineer
Successful developers spend only 40% of their time writing code. They spend the remaining 60% configuring and optimizing underlying infrastructure to run workloads and scale efficiently. Whether they are using cloud platforms or on-premises environments, organizations should conduct preliminary analysis and setup to ensure an optimum infrastructure with maximum utilization. This step allows organizations to avoid massive overhead in today’s competitive data industry.
Serverless Spark abstracts infrastructure concerns, giving developers the time to focus on constructing code. This ensures that resources and usage are based on demand, resulting in gained work hours and capital costs in maintaining the infrastructure. As the newest member to Google Cloud’s suite of managed services, Serverless Spark allows users to build robust, powerful and efficient data processing pipelines across various Google Cloud Platform (GCP) solutions.
As a Google Cloud Premier Partner, we’re sharing the benefits of Serverless Spark and how to implement Spark structured streaming in GCP.
What Is Serverless Spark on Google Cloud?
Serverless Spark is an autoscaling solution that seamlessly integrates with GCP and open-source tools so that the user can effortlessly power extract, transform and load (ETL), data science, and data analytics at scale. GCP has been running large-scale, business-critical Spark workloads for enterprise customers for more than six years through Dataproc, a service that leverages open-source data tools.
What Benefits Can Serverless Spark Drive for Your Data Infrastructure?
- Eliminate time spent managing Spark clusters. With Serverless Spark, users submit their Spark workloads and GCP removes the application dependency on the operating environment, allowing applications and data to move freely from physical to virtual and cloud-based platforms. The workload can then acquire resources on demand and auto-scale without planning.
- Enable access to data for users at all levels. Connect, analyze and execute Spark jobs from the interface. Users can choose interfaces such as BigQuery, Vertex AI or Dataplex that focus on pipeline execution code while keeping the experience uniform across services.
- Retain flexibility of consumption. In practical scenarios, there is no one-size-fits-all solution when it comes to data pipelines. Serverless Spark provides flexibility of peripheral integrations with workloads based on requirements and offers basic resource management to help track costs and overall project resources consumption.
GCP Services Used to Implement Spark Structured Streaming using Serverless Spark
Dataproc is a fully managed and highly scalable service for running Apache Spark, Apache Flink, Presto and 30+ open-source tools and frameworks. It is ideal for data lake modernization, ETL and secure data science at scale; it is fully integrated with GCP’s other services. Dataproc allows users to work with commonly used open-source tools, algorithms and programming languages while seamlessly incorporating them into cloud-scale data sets. Data scientists and engineers can quickly access data and build data applications connecting Dataproc to BigQuery, Vertex AI, Cloud Spanner, Pub/Sub, or Data Fusion. The Dataproc Persistent History Server (PHS) web allows users to view job histories for jobs that run on active or deleted Dataproc clusters. The PHS accesses and displays Spark and MapReduce job history files and YARN log files written to Cloud Storage during the lifetime of Dataproc job clusters.
BigQuery is GCP’s fully managed data warehouse that has built-in features like machine learning (ML), geospatial analysis and business intelligence (BI). BigQuery provides data analytics that help users understand their data, gain business insights and aid in decision-making without infrastructural management. Its scalability and flexibility enables users to query terabytes of data within seconds and acquire data storage. BigQuery is widely used to analyze data, which is why it has become an important tool for data analysts, business analysts and ML engineers. Analytics features available in BigQuery include ad hoc analysis, geospatial analysis, ML and BI.
How to Implement Spark Structured Streaming in GCP Using Serverless Spark
Spark Structured Streaming in GCP can use Serverless Spark to create a retail data set in JavaScript Object Notation (JSON) format. The JSON is then processed by a Dataproc serverless batch running in streaming mode before finally being written to a BigQuery data set. The data set here can also be replaced by any other input data set.
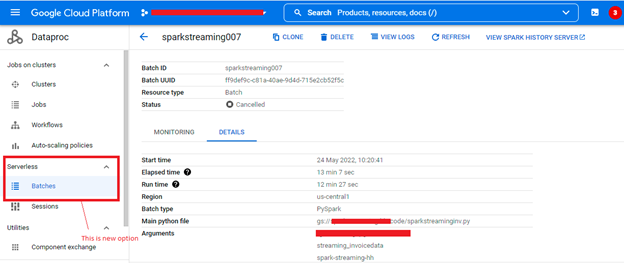
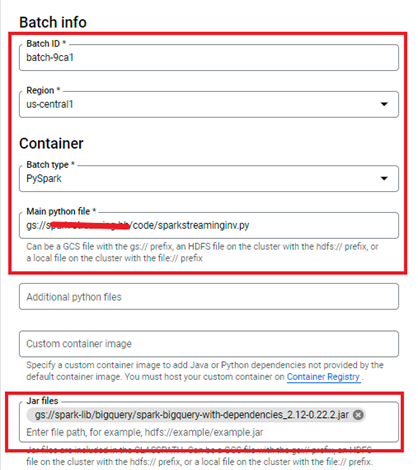
The values provided to the batch:
- Batch ID (Required): A unique identifier for your batch.
- Region (Required): The region where the batch will be created.
- Batch Type (Required): The type of batch such as Spark, PySpark, SQL or R.
- Main Python File (Required): The path to the main Python file for the batch.
- Jar Files (Optional): Additional dependencies (if required). When writing the data to BigQuery, provide Spark a BigQuery connector as an additional dependency.
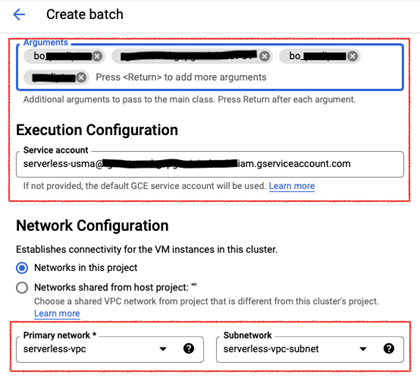
- Arguments (Optional): Runtime arguments referenced in the application code.
- Service Account (Optional): A user-managed service account that has the required roles and permissions for execution of the serverless batch.
- Network Configuration (Required): A virtual private cloud network and subnetwork that has Private Google Access enabled.
- History Server Cluster (Optional): A Dataproc PHS is a Dataproc cluster used to store application logs accessible through Spark UI.
2. Submit the streaming job once the batch is configured. On the autoscaling side, GCP will, by default, abstract the calculation and provisioning of the number of executors to run the job optimally but, using Spark properties, parts of the job can be manually overridden. When new data arrives at the source through Google Cloud Storage Bucket, the Serverless Spark batch reads the data, processes it and pushes the data into BigQuery. The Serverless Spark batch is set up to ingest streaming data using two Spark configurations:
- spark.streaming.stopGracefullyOnShutdown
- spark.sql.streaming.schemaInference
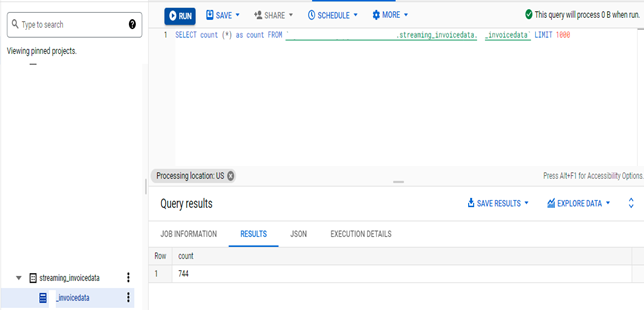
When the data is written into a BigQuery table, analytical queries can be run against the data.
Note: The Spark Structured Streaming job is designed to read incoming real-time data delivered to a storage directory and process it.
Output:
Logging and Monitoring in GCP
Visualize data on charts and dashboards and create alerts to get notifications when metrics are outside of expected ranges to inform real-time decisions quickly and efficiently.
- A fully managed service that performs at scale and can ingest application and platform log data, as well as custom log data from Google Kubernetes Engine (GKE) environments, virtual machines, and other services inside and outside of Google Cloud.
- Advanced performance, troubleshooting, security and business insights all come from Log Analytics, integrating the power of BigQuery into Cloud Logging.
Cloud Monitoring:
- Provides visibility into the performance, uptime and overall health of cloud-powered applications.
- Collect metrics, events and metadata from Google Cloud services.
- Hosts uptime probes, application instrumentation and a variety of common application components.
Dataproc Serverless Batch Logging:
- Logs associated with a Dataproc Serverless batch can be accessed from the logging section within Dataproc>Serverless>Batches<batch_name>
.
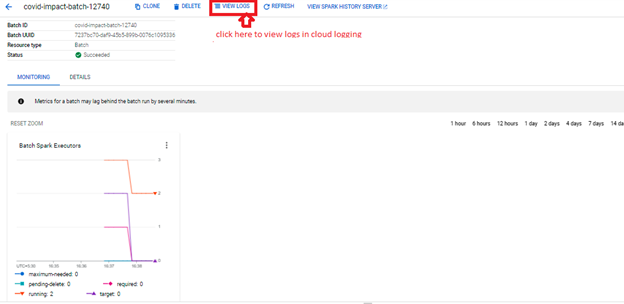
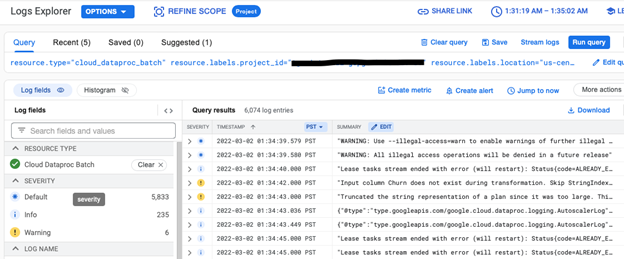
3. Click on “View Logs” button on the Dataproc batches monitoring page to get to the Cloud Logging page. This allows you to analyze the logs for a specific Serverless Spark batch.
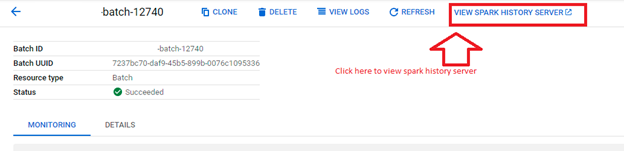
4. To view the Persistent History server logs, click the “View History Server” button on the Dataproc batches monitoring page, so the logs show below:
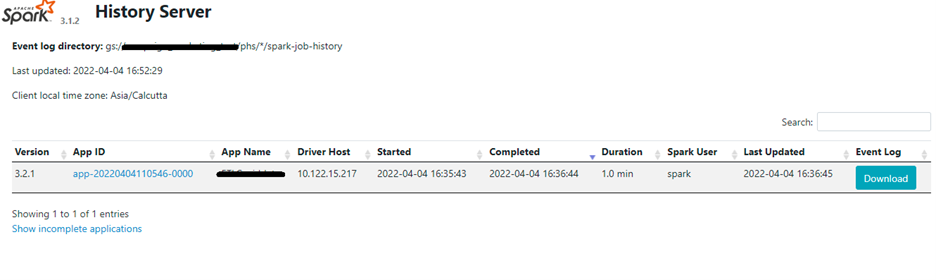
PHS logs provide insight into job history with respect to Spark properties, directed acyclic graphs (DAGs), lineage graph, executors, driver resource management and so forth, whereas cloud logging provides information about the batch job bootup script and other parameters set for the job as well as the output.
Serverless Spark vs. Dataproc on Compute Engine Clusters
|
Capability |
Dataproc Serverless for Spark | Dataproc on Compute Engine |
| Processing Frameworks | Spark 3.2 | Spark 3.1 and earlier versions. Other open-source frameworks, such as Hive |
| Serverless | Yes | No |
| Startup Time | ~45 s | 90 s |
| Infrastructure Control | No | Yes |
| Resource Management | Spark-based |
YARN-based |
| GPU Support | Planned | Planned |
| Interactive Sessions | Planned (Google Managed) | Planned (Customer Managed) |
| Custom Containers | Yes | No |
| VM Access (for example, SSH) | No | Yes |
| Java Versions | Java 11 | Pervious Versions Supported |
| OS Login Support* | No | Yes |
Use Serverless Spark to Drive Efficiency and Accelerate Your Business
Serverless Spark can help streamline data processing pipelines and optimize workloads across GCP solutions. Taking these steps to ensure efficiencies in your data infrastructure can power your business to reach its goals and stay ahead of the competition.
Sources
- What is BigQuery, Google Cloud
- Serverless Spark jobs for all data users, Google Cloud
- Dataproc, Google Cloud
Our Approach
As a Google Cloud Premier Partner, we support the full spectrum of delivering Google Cloud Platform (GCP) initiatives. From design to implementation—we’re there every step of the way to help you navigate today’s complex, multicloud environment, maximize your investments and build for the future.
The information provided in this article is for educational and informative purposes only and is intended to inform readers and should not be understood as a guarantee or assurance of future success in any matter. Every system is different, and no specific outcome is guaranteed using the platforms mentioned here, such as Serverless Spark.
About the Author

Hemanth Aaileni is a software and data engineer at TEKsystems Global Services experienced in building intensive data applications, and well-versed with big data warehouses and analytics including Apache Spark, Python, Airflow, Dataproc, AWS Redshift, AWS EMR and BigQuery.